
A visual exploration of the softmax function

The softmax function \(\sigma(\mathbf{z})\) maps vectors to the probability simplex, making it a useful and ubiquitous function in machine learning. Formally, for \(\mathbf{\mathbf{z}} \in \mathbb{R}^{D}\),
To get an intuition for its properties, we'll depict the effect of the softmax function for \(D=2\). First, for inputs coming from an equally-spaced grid (depicted in red), we plot the softmax outputs (depicted in green):

The output points all lie on the line segment connecting (x=0, y=1) and (x=1, y=0). This is because, given 2-dimensional inputs, the softmax maps to the 1-dimensional simplex, the set of all points in \(\mathbb{R}^2\) that sum to 1. Thus, the softmax function is not one-to-one (injective): multiple inputs map to the same output. For example, all points along the line \(y=x\) are mapped to \((0.5, 0.5)\).
More interestingly, for any output (green dot), the inputs (red dots) that map to it are all located along 45-degree lines, i.e. lines parallel to the line \(y=x\). This is not an accident: the softmax function is translation-invariant. Formally, for any \(\alpha\):
\[\sigma(\mathbf{z}) = \sigma(\mathbf{z} + \alpha \mathbb{1}).\]
Next, we plot the effect of the softmax function on points already lying within the probability simplex. For inputs (in red) equally spaced between \((0, 1)\) and \((1, 0)\), we plot their softmax outputs (in green):
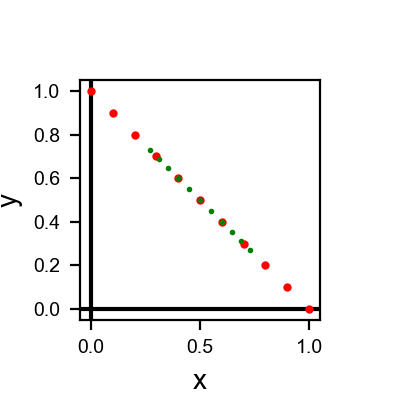
What this reveals is that the softmax shrinks inputs towards the point \((0.5, 0.5)\). Except when the input already represents a uniform distribution over all \(D\) classes, the softmax function is not idempotent.
We can illustrate this further by plotting equally-spaced softmax outputs (as colored points in \(\mathbb{R}^2\)), and then drawing curves with matching colors to depict the set of inputs which map to a particular output. Due to translation invariance, these curves will actually be lines, as depicted below.

Notice that it becomes increasingly difficult to produce high-confidence outputs. For a particular softmax output \((c, 1-c)\), the corresponding set of inputs is the set of all points of the form \((x, x + \log((1-c)/c) \). Even though the outputs are equally-spaced (0.1, 0.9), (0.2, 0.8), and so on, the inputs are increasingly distant when the probability mass is concentrated on either \(x\) or \(y\).
Suppose that we wanted to make the softmax function a bit more idempotent-ish. One way to do this is by using the temperature-annealed softmax (Hinton. et al., 2015):
\[[\sigma(\mathbf{z})]_i = \frac{e^{\mathbf{z}_i/\tau}}{\sum^D_{d=1}e^{\mathbf{z}_d/\tau}},\]
where \(\tau\) can be thought of as a temperature. Typically, one uses a cooled-down softmax with \(\tau < 1\), which leads to greater certainty in the output predictions. This is especially useful in inducing a loss function that focuses on the smaller number of hard examples, rather than on the much larger number of easy examples (Wang & Liu, 2021).
To visualize this effect, we repeat the previous plot, but now with \(\tau=0.5\):

We see that we can now "get by" with smaller changes in the inputs to the softmax. But the temperature-annealed softmax is still translation-invariant.
Code for these plots is on GitHub.
Hinton, Geoffrey, Oriol Vinyals, and Jeff Dean. "Distilling the knowledge in a neural network." arXiv preprint arXiv:1503.02531 2.7 (2015).
Wang, Feng, and Huaping Liu. "Understanding the behaviour of contrastive loss." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. (2021).